In today's rapidly evolving digital landscape, understanding the core mechanics of AI isn't just for developers – it's a strategic advantage for every freelancer. This guide demystifies Attention Variants in Transformers, from foundational Scaled Dot-Product to groundbreaking Flash Attention, equipping you with the knowledge to better leverage and troubleshoot the AI tools that power your business.
What Exactly Are Transformers and Attention Mechanisms?
If you've used ChatGPT, Bard, or any advanced AI writing assistant, you've interacted with a Large Language Model (LLM). And chances are, that LLM is built upon a revolutionary architecture called the Transformer. Introduced by Google in 2017, Transformers fundamentally changed how AI models process sequential data like text, making them incredibly powerful for tasks from translation to complex content generation.
At the heart of every Transformer is something called the Attention Mechanism. Imagine you're reading a very long document. Instead of trying to remember every single word equally, your brain naturally focuses on the most important keywords, phrases, and their relationships to understand the overall meaning. The Attention Mechanism does something similar for AI models.
Before Attention, older models (like Recurrent Neural Networks or RNNs) struggled with long sequences. They processed information word by word, making it hard to connect a word at the beginning of a sentence to one at the end. Attention allows the model to "look" at all parts of the input sequence simultaneously and assign different levels of importance (or "attention") to each part when processing a specific word. This means it can understand long-range dependencies and context much more effectively, leading to the coherent and contextually relevant outputs we see from modern LLMs.
Why Should Freelancers Care About Attention Variants?
You might be thinking, "I'm a graphic designer, a writer, a marketer – why do I need to understand the nitty-gritty of AI architecture?" The answer is simple: empowerment and competitive advantage.
- Optimize Your AI Tools: Understanding how attention works helps you craft better prompts, interpret AI outputs more accurately, and even troubleshoot when an AI tool seems to "miss the point." You'll learn why context windows matter and how different models handle information.
- Strategic Decision-Making: When choosing between AI tools or evaluating their capabilities, knowledge of attention variants helps you understand their underlying strengths and limitations. Is one model better at long-form content because of its attention mechanism? Is another faster due to efficiency improvements?
- Identify Opportunities: As AI technology evolves, new tools emerge that leverage these advancements. Being aware of concepts like Flash Attention means you can identify cutting-edge solutions that offer significant speed or capacity advantages, potentially giving you an edge in your service offerings.
- Communicate with Confidence: Whether you're discussing project requirements with clients or collaborating with AI developers, a basic grasp of these concepts allows you to speak the language of modern AI, fostering trust and clearer communication.
- Future-Proof Your Skills: AI isn't a fad; it's a foundational technology. Investing a little time in understanding its core principles makes you more adaptable and resilient in a rapidly changing professional landscape. You're not just a user; you're an informed participant.
The Evolution of Attention: From Core Concept to Cutting-Edge Efficiency
The Attention Mechanism isn't a static concept; it has evolved significantly since its inception. Each variant brings improvements, addresses limitations, or specializes in certain tasks. Let's break down the most important ones.
Scaled Dot-Product Attention: The Foundation
This is the original, fundamental building block of the Transformer's attention mechanism. It's elegantly simple yet incredibly powerful.
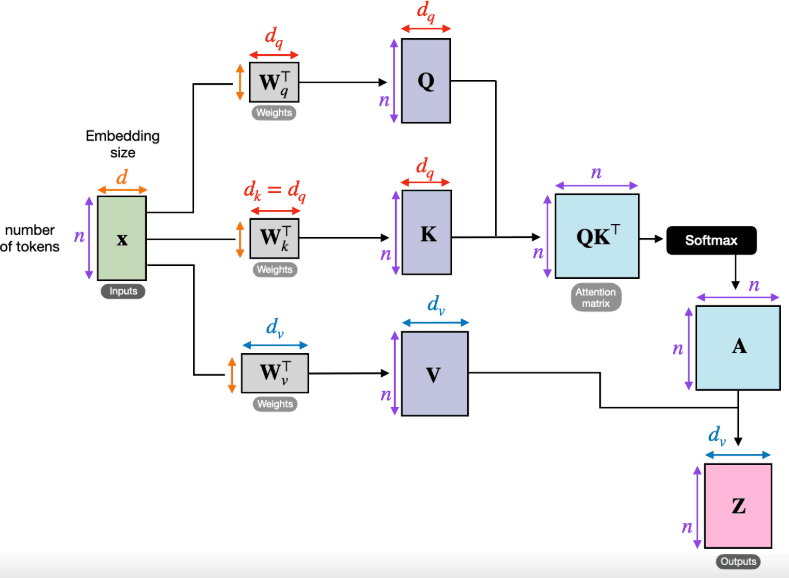
Imagine each word or token in your input sequence is represented by three different vectors (mathematical representations):
- Query (Q): This is like asking a question. For each word, it asks, "What should I pay attention to?"
- Key (K): These are like labels or indices for all other words. They answer, "What am I?"
- Value (V): These are the actual content or information associated with each word. They answer, "What information do I hold?"
Scaled Dot-Product Attention works by comparing the Query of one word against the Keys of all other words (including itself). The more similar a Query is to a Key (measured by a "dot product"), the more "attention" that word receives. These similarity scores are then scaled and used to weight the Value vectors. Essentially, words with higher attention scores contribute more of their "value" to the output representation of the current word.
Pros of Scaled Dot-Product Attention:
- Simplicity: Conceptually straightforward and easy to implement.
- Effectiveness: Highly successful in capturing long-range dependencies in data, a major breakthrough.
- Parallelization: Unlike RNNs, it can process all input tokens simultaneously, leading to faster training.
Cons of Scaled Dot-Product Attention:
-
Quadratic Complexity: The biggest drawback. If your input sequence has
Ntokens, calculating attention requires comparing each Query to every Key, resulting inNN(N-squared) operations. This means memory usage and computation time explode as sequence length increases. This is why LLMs have context window limits. - Memory Intensive: Storing the N x N attention matrix can consume vast amounts of memory, especially for long sequences, limiting the practical context window.
Multi-Head Attention: Enhancing Focus and Robustness
While Scaled Dot-Product Attention is powerful, it might only capture one type of relationship between words. Think of it like looking at a problem from a single perspective. Multi-Head Attention addresses this by allowing the model to look at the same input from multiple perspectives simultaneously.
Instead of just one set of Q, K, and V vectors, Multi-Head Attention employs several "heads." Each head independently performs its own Scaled Dot-Product Attention. Each head learns to focus on different aspects of the relationships. For example, one head might learn grammatical dependencies, while another learns semantic meanings, and yet another focuses on coreference resolution.
The outputs from these multiple heads are then concatenated (joined together) and linearly transformed to produce the final attention output.
Pros of Multi-Head Attention:
- Rich Representations: Captures a wider variety of relationships and dependencies in the data, leading to more robust and nuanced understanding.
- Improved Performance: Consistently leads to better model performance across a range of tasks.
- Parallel Processing: Each head can operate in parallel, maintaining the speed benefits of the Transformer architecture.
Cons of Multi-Head Attention:
- Increased Parameters: More heads mean more learnable parameters, making the model larger.
- Still Quadratic: While parallel, each individual head still computes attention with quadratic complexity, so the overall memory and computational cost for long sequences remains an issue.
Causal (Masked) Attention: The Magic Behind Text Generation
When an LLM generates text, it does so word by word. For instance, when it's predicting the next word, it should only consider the words it has already generated or been given as input. It shouldn't "peek" at future words it's about to generate, as that would be cheating and wouldn't reflect real-world generation.
Causal Attention (also known as Masked Attention) enforces this rule. It's a modification to Scaled Dot-Product Attention where, during the calculation of attention scores, any connection to "future" tokens is simply blocked or "masked out." This ensures that a token can only attend to itself and preceding tokens in the sequence.
Pros of Causal Attention:
- Enables Generation: Absolutely crucial for autoregressive models (like most LLMs) that generate sequences token by token.
- Prevents Data Leakage: Ensures the model doesn't "cheat" by seeing future information during training or generation.
Cons of Causal Attention:
- Specific Use Case: Primarily used in generative tasks; not suitable for tasks where full bidirectional context is required (e.g., translation where you need to see the whole sentence).
- Doesn't Solve Quadratic Cost: While it modifies how attention is computed, it doesn't fundamentally change the quadratic computational or memory complexity.
Flash Attention: Revolutionizing Efficiency
The quadratic complexity of standard attention was a major bottleneck, limiting the context window of LLMs and increasing the cost of training and inference. Enter Flash Attention, a groundbreaking innovation from Stanford University that significantly improves the speed and memory efficiency of attention calculations.
Flash Attention doesn't change the mathematical output of attention; rather, it changes how
• it's computed to be far more hardware-efficient. The key insight is to reduce the number of times the GPU has to move data between its fast but small SRAM (on-chip memory) and its slower but larger HBM (High Bandwidth Memory, like DRAM).
It achieves this through techniques like:
- Tiling: Instead of processing the entire attention matrix at once, it breaks it down into smaller blocks (tiles) that can fit into the faster SRAM.
- Recomputation: Instead of storing the large attention matrix in HBM, it recomputes certain intermediate values on the fly within SRAM when needed. This trades a small amount of extra computation for a large reduction in slow memory transfers.
The result is a dramatic speedup (often 2-4x faster) and a significant reduction in memory usage, allowing for much larger context windows and more economical training of advanced LLMs.
Pros of Flash Attention:
- Massive Speedup: Dramatically faster training and inference for Transformer models.
- Reduced Memory Footprint: Enables models to process much longer sequences (larger context windows) with the same hardware.
- Cost Reduction: Faster training means less GPU time, translating to lower operational costs for AI development and deployment.
- Enables Larger Models: Opens the door for even more powerful LLMs with extended context understanding.
Cons of Flash Attention:
- Implementation Complexity: More intricate to implement compared to standard attention, requiring deep understanding of GPU architecture.
- Hardware Specificity: Optimized for specific GPU architectures (like NVIDIA's Tensor Cores), which might not be universally available or efficient on all hardware.
- Still an Active Area: While incredibly effective, research continues to find even more optimized attention mechanisms.
Pros and Cons of Deep-Diving into Attention Variants for Freelancers
Deciding to invest time in understanding these technical nuances comes with its own set of advantages and disadvantages for the average freelancer.
Pros for Freelancers:
- Enhanced AI Literacy and Strategic Insight: You move beyond being a mere user to an informed strategist. This allows you to speak authoritatively about AI capabilities and limitations with clients and peers.
- Better Prompt Engineering and AI Tool Utilization: A deeper understanding helps you anticipate how an AI will process your input, leading to more effective prompts and superior results from tools. You'll know why a longer context window matters for complex tasks.
- Competitive Edge in AI-Driven Projects: As more industries adopt AI, freelancers who understand the underlying tech can offer more sophisticated solutions, troubleshoot effectively, and differentiate themselves in the marketplace.
- Ability to Communicate More Effectively with AI Developers/Clients: Bridging the gap between business needs and technical implementation becomes easier. You can articulate requirements or issues with greater precision.
- Potential for New Service Offerings: With this knowledge, you might identify niches for AI consulting, custom AI integration, or specialized prompt engineering services that leverage advanced AI features.
Cons for Freelancers:
- Steep Learning Curve for Non-Technical Freelancers: The concepts can be abstract and mathematically intensive. It requires dedication to grasp without a background in computer science or machine learning.
- Time Investment That Might Not Directly Translate to Immediate Revenue: The time spent learning might not yield immediate, tangible financial returns, especially for those whose primary work doesn't directly involve AI development.
- Can Feel Overly Academic if Not Tied to Practical Applications: Without connecting these concepts back to how they impact the AI tools you use daily, the learning can feel abstract and irrelevant.
- Rapid Pace of AI Research Means Constant Updates: The field of AI is moving incredibly fast. What's cutting-edge today might be commonplace tomorrow, requiring continuous learning to stay current.
NerdsTool's Rating for Understanding Attention Variants: 9/10
At NerdsTool, we rate the value of a freelancer understanding Attention Variants in Transformers a strong 9 out of 10. While it's a deep dive into technical territory, the insights gained are invaluable for anyone serious about mastering AI tools and staying ahead in the modern freelance economy. This knowledge empowers you to not just use AI, but to truly understand its capabilities, limitations, and future trajectory. It transforms you from a casual user into an informed power user and strategic thinker.
Conclusion: Beyond the Prompt – Mastering the AI Core
The world of AI is no longer a black box solely for data scientists. As freelancers, the tools powered by these sophisticated models are becoming indispensable to our daily workflows. By taking the time to understand the foundational concepts like Attention Variants – from the core Scaled Dot-Product to the efficiency-boosting Flash Attention – you unlock a new level of mastery.
This isn't about becoming an AI developer, but about becoming an AI-literate professional. It's about optimizing your AI usage, troubleshooting with confidence, making smarter tool choices, and ultimately, future-proofing your freelance career in an increasingly AI-driven world. The more you understand how these powerful tools "think," the better you can direct them to achieve your goals.
Ready to Transform Your AI Understanding?
Don't let complex terminology intimidate you. Start exploring! Engage with the AI tools you use daily with a newfound perspective. Experiment with context windows, observe performance differences, and see how your deeper understanding translates into more effective and efficient work. Share your insights and questions with the NerdsTool community – let's learn and grow together in this exciting AI frontier!

