Key Takeaways
- NVIDIA NeMo AutoModel significantly speeds up fine-tuning of large transformer models, especially Mixture-of-Experts (MoE) architectures.
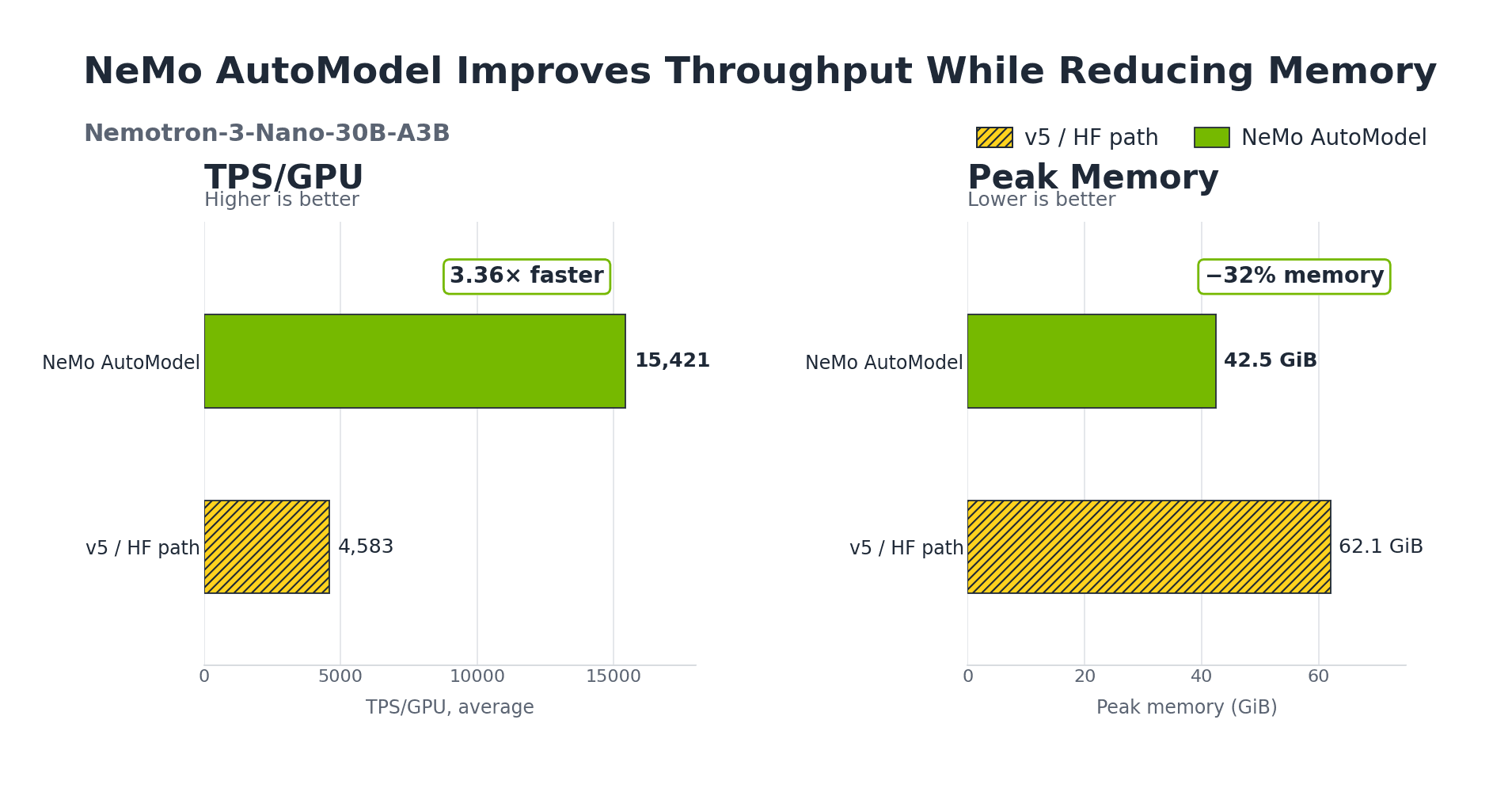
- It offers 3.4-3.7x higher training throughput and 29-32% less GPU memory compared to native Hugging Face Transformers v5 for certain MoE models.
- The library is open-source, built on PyTorch DTensor, and provides day-zero compatibility with Hugging Face models, requiring minimal code changes.
- It leverages advanced parallelism (FSDP2, HSDP, TP, PP) and custom NVIDIA CUDA kernels for optimal performance and scalability across single or multiple GPUs.
Accelerating Transformer Fine-Tuning with NVIDIA NeMo AutoModel
The world of Artificial Intelligence is moving at an incredible pace, and at its heart are transformer models – the powerhouses behind large language models (LLMs) and vision-language models (VLMs). These models have changed how we interact with AI, but training and fine-tuning them can be a huge challenge. It often demands significant computational resources, expertise, and time.
That's where NVIDIA NeMo AutoModel comes in. As part of the broader NVIDIA NeMo framework, AutoModel is designed to make the process of fine-tuning these complex transformer models much faster, more efficient, and more accessible for developers and researchers. It's about taking the pain out of large-scale AI model customization, allowing you to focus more on innovation and less on infrastructure headaches.
What Exactly is NVIDIA NeMo AutoModel?
NVIDIA NeMo AutoModel is an open-source library built on PyTorch DTensor, using a Single Program, Multiple Data (SPMD) architecture. It's specifically designed to help developers scale the training and fine-tuning of LLMs and VLMs. Think of it as a specialized toolkit within the larger NVIDIA NeMo framework, which is an end-to-end platform for building, customizing, and deploying generative AI models.
The core idea behind AutoModel is to provide highly optimized model implementations while maintaining compatibility with popular frameworks like Hugging Face Transformers. This means you can often take your existing Hugging Face code, make a small change to an import line, and immediately benefit from NVIDIA's performance optimizations.
Why is Accelerating Transformer Fine-Tuning So Important?
Fine-tuning large transformer models is a critical step for adapting a general-purpose model to specific tasks or datasets. However, it comes with several challenges:
- Resource Intensive: Training these models requires immense GPU power and memory, especially for frontier-scale models or Mixture-of-Experts (MoE) architectures.
- Time Consuming: Without optimizations, fine-tuning can take days or even weeks, slowing down development cycles.
- Complexity: Managing distributed training, memory optimization, and various parallelism strategies can be difficult for developers.
- Cost: Extended training times on cloud GPUs directly translate to higher operational costs.
Accelerating this process directly tackles these issues. It means faster experimentation, quicker deployment of specialized AI models, reduced operational costs, and ultimately, making advanced AI more accessible to a broader range of practitioners. For software developers and machine learning engineers, this translates to more productive workflows and the ability to iterate on models much more rapidly.
How Does NeMo AutoModel Work Its Magic?
NVIDIA NeMo AutoModel achieves its impressive speedups and memory efficiencies through a combination of sophisticated techniques, all designed to work seamlessly with PyTorch and Hugging Face.
PyTorch DTensor and SPMD Architecture
At its foundation, AutoModel uses PyTorch's native SPMD model with DTensor and DeviceMesh. This approach allows the same training script to run efficiently on anything from a single GPU to hundreds or even thousands of GPUs in a multi-node cluster, simply by adjusting the mesh configuration. This makes parallelism a matter of configuration rather than complex code changes, decoupling the model code from the parallel strategy.
Advanced Parallelism Strategies
To handle the sheer size of modern transformer models, NeMo AutoModel employs a suite of advanced parallelism techniques:
- Fully Sharded Data Parallelism v2 (FSDP2): This is a key distributed training strategy that shards model parameters, gradients, and optimizer states across GPUs, drastically reducing memory consumption per device.
- Hybrid Sharding Data Parallelism (HSDP): An extension of FSDP2, HSDP is optimized for scaling across multiple nodes.
- Tensor Parallelism (TP): Partitions model tensors (like weights) across GPUs.
- Context Parallelism (CP): Splits sequence contexts to enable handling extended context windows.
- Pipeline Parallelism (PP): Divides the model layers into stages, with each stage running on a different GPU, allowing for a pipeline of data to flow through the model. It's composable with FSDP2 and DTensor, enabling powerful 3D parallelism.
For Mixture-of-Experts (MoE) models, AutoModel introduces Expert Parallelism (EP). This is crucial for models like Mixtral or Qwen2 MoE, where the "experts" (sub-networks) can be sharded across GPUs. For example, with EP=8 on 8 GPUs, each GPU only needs to hold 1/8th of the expert parameters, significantly reducing memory pressure and allowing for much larger models or batch sizes.
Custom Optimized Kernels
NVIDIA doesn't just rely on standard PyTorch operations. NeMo AutoModel integrates custom CUDA kernels for critical operations, including:
- TransformerEngine: Provides highly optimized attention and fused linear layers.
- DeepEP: A fused all-to-all dispatch mechanism that optimizes communication with computation for MoE models, further boosting throughput.
- FlexAttn: Additional attention optimizations for specific model architectures.
These hand-tuned implementations deliver exceptional performance, with benchmarks showing up to 279 TFLOPs/sec/GPU for models like GPT-OSS (20B) on 8 GPUs.
Memory Efficiency Techniques
Beyond parallelism and custom kernels, AutoModel includes other memory-saving features:
- FP8 Mixed Precision Training: Utilizing 8-bit floating-point numbers reduces memory footprint and can increase throughput on compatible hardware.
- Activation Checkpointing: Trades computation for memory by recomputing activations during the backward pass instead of storing them.
- Sequence Packing: Efficiently combines multiple shorter sequences into a single longer one to fully utilize GPU capacity.
Key Features and Benefits for AI Practitioners
NeMo AutoModel brings a robust set of features that directly benefit developers and researchers working with large AI models:
- Day-Zero Hugging Face Compatibility: This is a massive advantage. You can fine-tune virtually any model from the Hugging Face Hub without needing to convert checkpoints. The
NeMoAutoModelForCausalLMclass subclasses Hugging Face'sAutoModelForCausalLM, ensuring a familiar API and a "zero-friction upgrade path." - Exceptional Performance and Scalability: As highlighted by benchmarks, AutoModel can deliver 3.4-3.7x higher training throughput and 29-32% less GPU memory on fine-tuning MoE models compared to native Transformers v5. This allows for training larger models or larger batch sizes, accelerating research and development.
- Comprehensive Training Workflows: It supports a wide range of fine-tuning approaches, including:
- Supervised Fine-Tuning (SFT): Full-parameter fine-tuning for task-specific adaptation.
- Parameter-Efficient Fine-Tuning (PEFT): Techniques like LoRA/QLoRA for memory-efficient adaptation by updating only a small subset of parameters.
- Pre-training: Support for training models from scratch, including large MoE models.
- Knowledge Distillation: Transferring knowledge from a larger "teacher" model to a smaller "student" model.
- Tool Calling and Quantization-Aware Training: For specialized applications and deployment-ready models.
- Flexible Checkpointing: NeMo AutoModel writes Distributed Checkpoints (DCP) using SafeTensors shards. These checkpoints can be merged into a single Hugging Face-compatible format for inference or sharing, and can be reshared or resumed from any point without manual intervention.
- Hackable and Configurable: The framework emphasizes linear training scripts and YAML-driven configuration. This means the training loop is always visible, making it easier to understand, debug, and customize without hidden abstractions.
- Open Source and NVIDIA Supported: As an open-source library under the Apache 2.0 license, it benefits from active maintenance and support from NVIDIA.
What This Means for AI Development
For software developers, machine learning engineers, and researchers, NVIDIA NeMo AutoModel represents a significant step forward in making advanced AI model development more practical and efficient. It means:
- Faster Iteration Cycles: The ability to fine-tune models much quicker allows for more experiments and faster progress in developing robust AI solutions.
- Democratization of Large Models: By reducing the computational barriers, more teams, even those with more modest GPU resources, can work with and customize large transformer models.
- Bridging Research and Production: The seamless compatibility with Hugging Face and optimized performance help bridge the gap between experimental research and deploying high-performance models in production.
- Focus on Innovation: Developers can spend less time optimizing low-level infrastructure and more time on model architecture, data curation, and novel applications.
While NeMo AutoModel itself is an open-source library, it's worth noting that it's part of the broader NVIDIA AI Enterprise platform, which offers enterprise-grade support and additional tools for large-scale deployments. The NVIDIA NeMo framework also includes other components like NeMo Speech for ASR/TTS and NeMo Agent Toolkit for building intelligent AI agents.
The release of NeMo AutoModel, alongside continuous updates to the NeMo framework (such as the scheduled June 2026 release of NeMo Speech after a repository split), underscores NVIDIA's commitment to providing cutting-edge tools for the AI community. Projects like the Nemotron family of open models, which are often trained using NeMo, further showcase the capabilities enabled by these tools.
Getting Started
To start exploring NVIDIA NeMo AutoModel, the best place is the official NeMo AutoModel documentation. This resource provides detailed installation guides, configuration examples, and tutorials for various fine-tuning workflows. You can also find the source code and contribute to the project on the NVIDIA NeMo GitHub repository.
Frequently Asked Questions
What is the NVIDIA NeMo framework?
NVIDIA NeMo is an open-source, state-of-the-art framework from NVIDIA for building, customizing, and deploying generative AI models, including large language models (LLMs), vision-language models (VLMs), and speech AI models. It provides tools for data curation, model customization, pre-training, retrieval-augmented generation (RAG), and guardrailing.
How does NeMo AutoModel improve fine-tuning speed?
NeMo AutoModel accelerates fine-tuning by leveraging several key technologies: advanced parallelism strategies (like FSDP2, HSDP, Tensor Parallelism, Expert Parallelism), custom NVIDIA CUDA kernels (such as TransformerEngine and DeepEP), and memory-efficient techniques (like FP8 mixed precision and activation checkpointing).
Is NVIDIA NeMo AutoModel free to use?
Yes, NeMo AutoModel is an open-source library released under the Apache 2.0 license. While the library itself is free, using it on NVIDIA GPUs might incur costs depending on your hardware setup or cloud service provider. The broader NVIDIA NeMo framework is also part of the NVIDIA AI Enterprise platform, which is a commercial offering with support and services.
Can NeMo AutoModel be used with existing Hugging Face models?
Absolutely. One of the main benefits of NeMo AutoModel is its "day-zero" compatibility with Hugging Face models. It's designed to seamlessly integrate with the Hugging Face ecosystem, often requiring just a single line change to import the AutoModel class to gain significant performance benefits.


